
Structured programming
구조적 프로그래밍: 현대에 일반적으로 사용하고 있는 방식으로, 프로그램이 위에서 아래로 선형적으로 읽히도록 만드는 것을 목표로 하는 패러다임 프로그램의 일부를 블랙박스로 구성하여 항상 모든 세부사항을 알 필요 없게 된다. 기본 도구 - 조건문, 반복문, 함수 호출 및 재귀 등
예시로 Swift에는 for문이 없고, Jump문이 있다고 가정해보자.
만약 0부터 100 사이 모든 짝수를 출력하려면 아래와 같이 작성해볼 수 있다.
var x = 0
top: if x.isMultiple(of: 2) {
print(x)
}
x += 1
if x <= 100 {
continue top
}특정 줄에 top: 과 같은 레이블을 붙이고, 실행 흐름을 해당 레이블로 이동시킬 수 있는 continue 를 사용한다고 가정해보자.
위와 같은 점프문은 저수준 어셈블리어에서 사용되던 방식이었다.
✔️ 점프문의 단점: 가독성
위와 같은 점프문은 가독성 측면에서 for문에 비해 좋지 않은 것을 볼 수 있다.
var x = 0
outer: var y = 0
inner: if x.isMultiple(of: 2) && y.isMultiple(of: 2) {
print(x, y)
}
y += 1
if y <= 100 {
continue inner
}
x += 1
if x <= 100 {
continue outer
}위와 같은 중첩 반복을 for문을 사용한다면,
for x in 0...100 {
for y in 0...100 {
if x.isMultiple(of: 2) && y.isMultiple(of: 2) {
print(x, y)
}
}
}훨씬 가독성이 좋다.
✔️ 점프문의 단점: 코드 영향 범위
점프문은 실행 지점을 코드 어느 줄로든 이동시킬 수 있다. 그렇기 때문에 특정 코드 줄을 이해하기 위해서는 해당 줄로 실행이 이동했을 가능성이 있는 모든 다른 코드들도 이해해야한다.
우리가 주로 사용하는 함수 호출과 동작 방식을 비교해보자면,
func add(_ lhs: Int, _ rhs: Int) -> Int {
lhs + rhs
}
add(3, 4)함수를 호출하면 해당 줄로 실행 이동하는 것 처럼 보이겠지만, add 함수가 접근할 수 있는 영역이 제한된다.
함수는 함수의 인수와 외부의 전역변수만 접근할 수 있으며, 함수가 완료되면 실행 흐름이 호출 시점으로 반환된다. 이러한 기능 덕분에 함수는 외부에서는 내부의 동작에 대해 신경쓰지 않아도 된다.
하지만, 점프문은 위와 같은 기능이 없다.
✔️ 점프문의 단점: 실행 흐름의 예측 불가능성
또 다른 문제점으로는 점프문이 있는 프로그램의 실행 흐름은 예측 불가능성이 너무 크고 이해하기 아려워 원하는 기능을 구현하기 어렵다.
예를들어 defer문을 생각해보자.
우리는 defer 문을 통해 함수 스코프의 끝에서 일부 로직을 실행하도록 할 수 있다.
defer { print("Outer loop finished") }
for x in 0...100 {
defer { print("Inner loop finished for", x) }
for y in 0...100 {
if x.isMultiple(of: 2) && y.isMultiple(of: 2) {
print(x, y)
}
}
}위의 코드처럼 defer를 통해 내부, 외부 for문이 종료되었음을 출력할 수 있다.
하지만 점프문에서는 이러한 기능을 사용할 수 없다. defer문이 어느 스코프에 속하는지 알 수 없기 때문에 defer문을 실행할 수 없다.
위와 같은 코드를 사용하려면 조건문 뒤에 print문을 삽입하는 수밖에 없다.
var x = 0
outer: var y = 0
inner: if x.isMultiple(of: 2) && y.isMultiple(of: 2) {
print(x, y)
}
y += 1
if y <= 100 {
continue inner
}
print("Inner loop finished", x)
x += 1
if x <= 100 {
continue outer
}
print("Outer loop finished")
만약 lock을 이용하여 내부를 잠근 후 count 변수를 증가시키는 작업을 할때, 점프 문을 사용하게 되면 다른 코드로 점프한 후 돌아오지 않을 가능성이 있다.
func increment() {
self.lock.lock()
self.count += 1
continue somewhereElse
self.lock.unlock()
}위와 같은 경우 잠금이 해제되지 않아 increment()메서드는 영원히 잠긴 상태가 된다.
점프문은 더 다양한 문제점들을 가지고 있고, 이러한 이유들 때문에 현재 우리가 사용하는 구조적 프로그래밍 언어는 중요한 연구 분야가 되었었다.
✔️ 구조적 프로그래밍 툴을 벗어난 Swift도구
Swift는 점프문을 제공하지는 않지만, 구조적 프로그래밍 틀을 벗어난 몇가지 도구를 제공한다.
첫번째 예로 새로운 스레드를 생성할 때를 생각해보자.
print("Before")
Thread.detachNewThread {
print(Thread.current)
}
print("After")실행 흐름 앞 뒤에 print문을 추가하면
Before
After
<NSThread: 0x10071c760>{number = 2, name = (null)}우리는 “After”가 출력 된 이후에 스레드 정보가 출력되는 것을 볼 수 있다.
이러한 경우는 코드가 위에서 아래로 흐르지 않는 것을 보여준다.
이렇게 위에서 아래로 흐르지 않는 방식은 Swift에서 익숙하게 사용하던 방식들이 깨지게 된다.
func thread() {
defer { print("Finished") }
print("Before")
Thread.detachNewThread {
print(Thread.current)
}
print("After")
}
thread()Before
After
Finished
<NSThread: 0x100710d70>{number = 2, name = (null)}스레드를 생성하기 전에 defer문을 추가하였을 때 스레드의 종료보다 defer문이 더 먼저 실행되는 것을 볼 수 있다.
스레드가 완전히 새로운 실행 흐름에서 동작하기 때문에 defer문은 스레드 작업이 끝나기를 기다릴 수 없다.
스레드 뿐만아니라 OperationQueue나 GCD 등에서도 마찬가지인데, 이는 스레드나 큐의 문제가 아니라 Escaping Closure와 관련된 문제이다.
Escaping Closure는 함수의 생명주기를 넘어 캡쳐되고 사용될 수 있는 클로저이다. Escaping Closure를 사용하게 되면 실행 흐름과 완전히 분리된 새로운 흐름을 만들어낼 수 있게 된다.
Structured Concurrency
구조적 동시성은 기존의 구조적 프로그래밍 방식처럼 동시성 컨텍스트에서도 코드를 작성할 수 있다.
이를 통해 비동기적이고 동시적인 작업을 하더라고 코드를 위에서 아래로 순차적으로 작성할 수 있으며, defer와 같은 기능을 사용할 수 있고, 코드의 실행 범위를 명확하게 구분하여 자원 정리와 같은 종료 작업을 쉽게 실행할 수 있다.
이전에 사용하였던 네트워크 통신 예제 코드를 통해 살펴보자.
requestId와 요청 시작 날짜 값을 TaskLocal 변수로 설정하여 작업 시 값에 접근하도록 할 수 있다.
enum RequestData {
@TaskLocal static var requestId: UUID!
@TaskLocal static var startDate: Date!
}
비동기 함수를 통해 데이터베이스 쿼리와 네트워크 요청 작업을 수행하고, requestId를 사용해 로그를 확인할 수 있다.
func databaseQuery() async throws {
let requestId = RequestData.requestId!
print(requestId, "Making database query")
try await Task.sleep(nanoseconds: 500_000_000)
print(requestId, "Finished database query")
}
func networkRequest() async throws {
let requestId = RequestData.requestId!
print(requestId, "Making network request")
try await Task.sleep(nanoseconds: 500_000_000)
print(requestId, "Finished network request")
}
그 다음 요청을 받아 처리하는 함수에서는 데이터베이스와 네트워크 요청을 처리하고 임시 응답값을 반환한다.
func response(_ request: URLRequest) async throws -> HTTPURLResponse {
let requestId = RequestData.requestId!
let start = RequestData.startDate!
defer { print(requestId, "Request finished in", Date().timeIntervalSince(start)) }
try await databaseQuery()
try await networkRequest()
return .init()
}위의 코드는 데이터베이스 쿼리 작업이 완료된 후에 네트워크 요청을 처리하는 직렬 작업 방식으로 수행되고있다. 그렇기 때문에 응답 시간이 오래 걸리게 된다. 해당 작업을 병렬화 하여 속도를 높일 수 있다.
위에서 사용한 방식으로 두 비동기 함수를 병렬화 하기 위해 Task 를 사용하여 각각 새로운 작업을 시작하도록 한다.
Task {
try await databaseQuery()
}
Task {
try await networkRequest()
}이러한 방식은 병렬적으로 작업을 수행하지만, 구조적 프로그래밍의 요소를 잃게 된다. Task를 사용하여 작업을 시작하게 되면 작업이 블로킹되지 않아 독립적으로 실행되므로 코드가 순차적으로 읽히지 않는다.
위에서 살펴본 Escaping closure를 사용하는 방식과 비슷한 구조인 것이다.
✔️ 구조적 동시성+병렬 작업 처리
두 작업이 병렬 작업으로 처리되면서 구조적 프로그래밍을 유지할 수 있는 방식에 대해 살펴보자.
Task 타입은 Task가 반환한 값에 접근할 수 있는 프로퍼티를 제공한다.
let task = Task {
try await Task.sleep(nanoseconds: NSEC_PER_SEC)
return 42
}
let number = try await task.valuetask.value 를 통해 반환되는 값에 접근할 수 있으며 await을 통해 접근해야 한다.
위의 프로퍼티를 활용하여 수정해보면,
let databaseTask = Task {
try await databaseQuery()
}
let networkTask = Task {
try await networkRequest()
}
try await databaseTask.value
try await networkTask.value각 작업을 변수에 할당하고, 반환하는 값을 await하면 된다.
코드가 직렬적으로 보이지만 실제로 두 작업은 병렬로 실행되고, 작업이 완료된 후 각 작업의 값에 접근하는 부분만 직렬로 수행된다. 그렇기 때문에 더 빠르게 작업을 완료할 수 있다.
실행해보면 약 0.5초의 시간만에 작업이 완료된다.
B2A20E2F-6389-4A0A-9BB0-9F6C2AB1FF86 Making database query
B2A20E2F-6389-4A0A-9BB0-9F6C2AB1FF86 Making network request
B2A20E2F-6389-4A0A-9BB0-9F6C2AB1FF86 Finished database query
B2A20E2F-6389-4A0A-9BB0-9F6C2AB1FF86 Finished network request
B2A20E2F-6389-4A0A-9BB0-9F6C2AB1FF86 Request finished in 0.552590012550354
비동기 작업을 동시에 실행하여도 구조적 프로그래밍의 틀을 벗어나지 않아도 된다.
하지만 이 코드는 간결하지 못하다. 두 작업을 완료할 때 까지 기다리기 위해 각각의 새로운 작업을 생성해야 하는 것이 좋아보이지 않는다.
미관적인 부분 뿐만아니라 취소 작업에서도 문제가 있다.
새로운 작업을 생성하게 되면 협력적인 취소를 수행하지 못하게 된다.
예를들어 위의 응답 작업을 시작하고 0.1초만에 취소한다고 해보자.
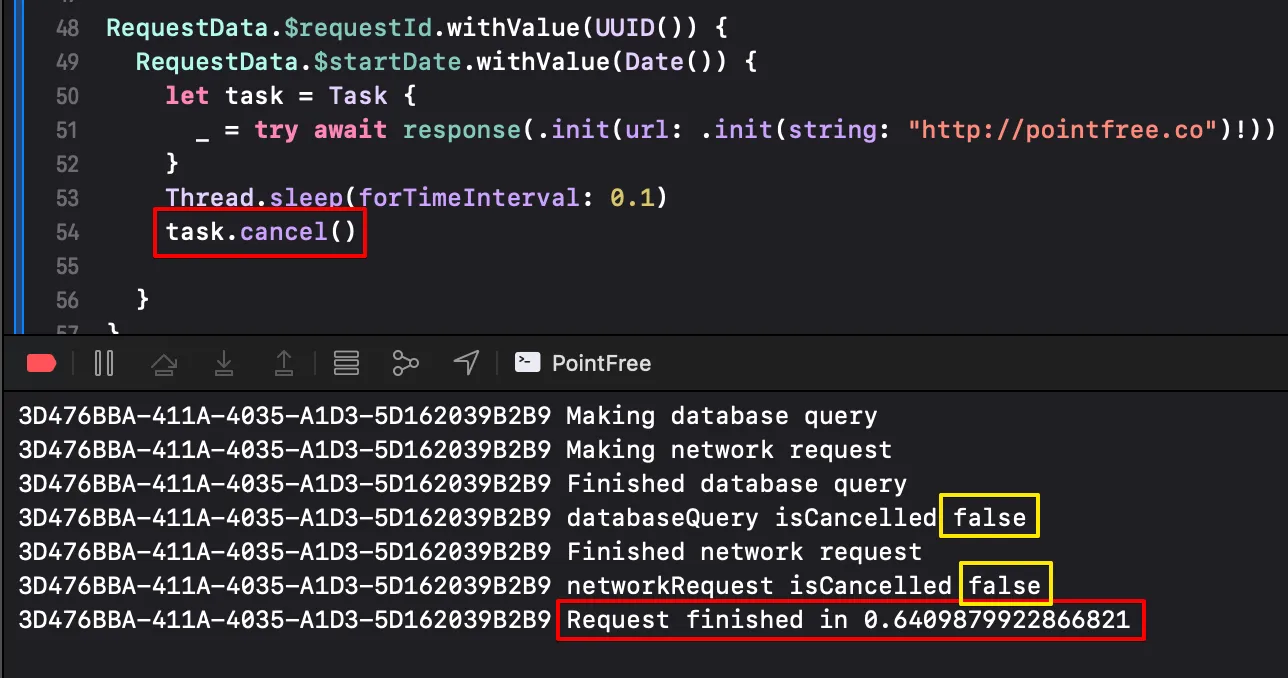
바로 실행 중인 두 작업이 취소되어 빠른 시간에 작업이 끝나길 원하지만 두 작업은 취소되지 않고 계속 작업을 수행하게 된다.
내부에서 새로운 Task를 생성하게되어 부모 작업과 독립적으로 실행을 하게되어 부모 작업의 취소를 전달받지 못하게 된다.
위와같이 동작하는 이유는 Apple의 구조적 동시성 설계 방식 때문이다. 작업을 생성하여 비구조적인 방식으로 동작하게 되면 해당 작업의 취소는 명시적으로 관리해야한다.
✔️ withTaskCancellationHandler
withTaskCancellationHandler 를 사용하여 비구조적 코드를 구조적 코드로 되돌리고, 취소도 우리가 원하는 대로 동작하도록 할 수 있다.
withTaskCancellationHandler(
operation: () async throws -> T,
onCancel: () -> Void
)operation 에서 실행할 비동기 작업을 처리하고, 취소가 감지되었을 때 onCancel 에서 취소 작업을 수행하게 된다.
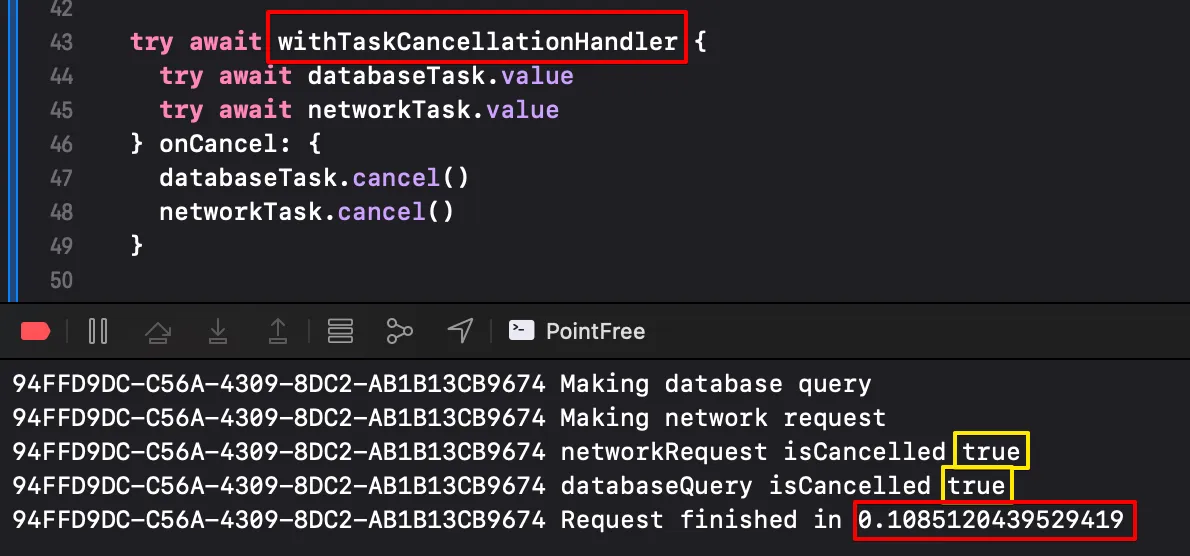
withTaskCancellationHandler 를 통해 내부 작업들이 취소 작업을 확인하게 된다.
하지만, 이 방법은 코드가 복잡해지는 문제점을 가지고 있다. 또, 위에서 아래로 읽히는 것 처럼 보이지만, 작업을 먼저 선언한 후, withTaskCancellationHandler 를 호출한 후 취소 로직과 작업 로직을 별도의 클로저로 구현해야 한다.
✔️ async let
더 간단하게 async let 을 사용해볼 수 있다.
async let 을 통해 여러 비동기 작업을 병렬로 실행하면서 코드가 선형적으로 읽히며 취소 작업도 전달할 수 있다.
async let databaseResponse = databaseQuery()
async let networkResponse = networkRequest()
만약, 두 비동기 함수가 각각의 데이터를 반환한다고 가정해보자.
struct User { var id: Int }
func fetchUser() async throws -> User { User(id: 42) }
struct StripeSubscription { var id: Int }
func fetchSubscription() async throws -> StripeSubscription { StripeSubscription(id: 1729) }위의 예시에서 async let 을 통해 병렬로 데이터를 처리할 수 있다.
async let user = fetchUser()
async let subscription = fetchSubscription()
이와 같이 async let 을 통해 가져온 변수는 await 키워드를 사용하여 접근할 수 있다.
try await user.id
이 병렬 작업 결과를 JSON으로 묶어 응답을 만들 수 있다.
struct Response: Encodable {
let user: User
let subscription: StripeSubscription
}
try await JSONEncoder().encode(Response(user: user, subscription: subscription))
async let user = fetchUser()
async let subscription = fetchSubscription()
let jsonData = try await JSONEncoder().encode(
Response(user: user, subscription: subscription)
)async let 을 활용하여 간단하고 선형적으로 코드가 읽히는 것을 볼 수 있다.
✔️ task group
async let 은 병렬 작업의 개수가 정해져있는 경우에 효과적으로 사용할 수 있지만, 작업 단위의 개수가 동적으로 정해지는 경우에는 다른 도구가 필요하다.
withTaskGroup 을 통해 동적인 개수의 작업을 수행하는 동안 실행을 중지하고, 모든 작업이 완료된 후 다시 실행을 하도록 할 수 있다.
withTaskGroup(
of: Sendable,
returning: GroupResult.Type,
body: (inout TaskGroup<Sendable>) async -> GroupResult
)첫번째 매개변수 of는 각 하위 task의 반환 타입을 의미한다.
두번째 매개변수인 returning 은 task group의 최종 반환 타입을 의미하고,body 는 task group에 task를 추가하고 실행하는 클로저이다.
예를들어, 1000개의 작업을 생성해 숫자를 모두 더하는 작업을 수행해보자.
먼저, 스레드를 기반으로 작업을 해보면
var sum = 0
for n in 1...1_000 {
Thread.detachNewThread {
Thread.sleep(forTimeInterval: 1)
sum += n
}
}1000개의 새로운 스레드를 생성한 후 작업을 처리하는데, 스레드를 사용하면 모든 스레드가 종료될 때 까지 기다려야 결과를 확인할 수 있다. 스레드 자체에 기다리는 작업이 없기 때문에 수동으로 대기 시간을 설정하여 기다려야 한다.
Thread.sleep(forTimeInterval: 2)
print(sum)위 코드를 수행하면 race condition 문제가 발생하게 되어 실행할 때 마다 다른 값을 출력하게 된다.
이 코드를 Task Group을 사용하는 방식으로 구현해보자.
withTaskGroup(of: Int.self, returning: Int.self) { group in
group.addTask(operation: () async -> Int)
}of와 returning에 Int 타입을 지정해주고, body에 task를 추가할 수 있다.
Task group에 task를 추가할 때는 addTask 메서드를 사용하게 된다.
추가되는 task는 매개변수가 없는 비동기 함수이며, of 에 지정한 타입을 반환해야 한다.
다음 코드는 1000개의 정수를 반복하며 1초동안 대기 후 반환하는 Task를 추가하는 코드이다.
Task {
await withTaskGroup(of: Int.self) { group in
for n in 1...1000 {
group.addTask {
try? await Task.sleep(nanoseconds: NSEC_PER_SEC)
return n
}
}
await group.waitForAll()
}
}모든 Task는 병렬로 실행되고, await group.waitForAll() 을 통해 모든 Task가 완료될 때 까지 기다릴 수 있다.
더 나아가서, 각 Task의 실행 결과를 수집할 수 있다. for await 을 이용하여 그룹 내에 있는 각 Task의 실행 결과에 접근할 수 있다.
var sum = 0
for await int in group {
sum += int
}
return sumTask group은 AsyncSequence 프로토콜을 준수한다. Sequence와 유사하지만 AsyncSequence는 next() 메서드를 사용하여 비동기적으로 작업의 결과를 순회하게 된다.
최종적으로, 1부터 1000까지의 숫자를 병렬적으로 계산하여 빠르게 수행하도록 하면
let sum = await withTaskGroup(of: Int.self, returning: Int.self) { group in
for n in 1...1_000 {
group.addTask {
try? await Task.sleep(nanoseconds: NSEC_PER_SEC)
return n
}
}
var sum = 0
for await int in group {
sum += int
}
return sum
}
print(sum)이와 같이 구현해 볼 수 있으며, 매 실행 마다 동일한 결과를 얻을 수 있다.
TaskGroup을 사용하여 Race Condition 문제를 해결할 수 있으며, 공유되는 가변 데이터에 동시적인 접근을 막기 위해 actor를 도입하지 않아도 된다.
✔️ TaskGroup의 작업 취소
TaskGroup은 협력적 취소를 지원한다. TaskGroup을 시작한 비동기 컨텍스트가 취소되었을 때 isCancelled 플래그를 통해 작업을 마무리하도록 할 수 있다.
addTaskUnlessCancelled 를 통해 상위 Task의 취소 여부를 확인하여 취소되었을 경우 Task를 추가하지 않도록 처리할 수 있다.
group.addTaskUnlessCancelled {
// 작업 추가
}
✔️ TaskGroup의 예외처리
TaskGroup에서 withThrowingTaskGroup 을 통해 비동기 작업에서 예외가 발생하거나 취소될 경우를 처리할 수 있다.
let sum = await withThrowingTaskGroup(of: Int.self, returning: Int.self) { group in
for n in 1...1_000 {
group.addTask {
try? await Task.sleep(nanoseconds: NSEC_PER_SEC)
return n
}
}
var sum = 0
for try await int in group {
sum += int
}
return sum
}
print(sum)
TaskGroup을 사용하여 여러 개의 Task를 병렬로 실행할 수 있고, 이러한 Task의 실행 결과를 모아 최종 결과로 누적하여 사용할 수 있다. 이러한 과정을 처리하면서도 구조적 프로그래밍을 유지하여 코드를 위에서부터 아래로 순차적으로 읽히도록 할 수 있다.
비동기 작업과 동시성 작업에서 구조적 프로그래밍 영역을 벗어나게 되는 도구들이 있지만, 가능한 구조적 프로그래밍을 유지할 수 있도록 노력해야 한다. async함수와 await문, async let, task group을 사용하면 복잡한 구조에서도 구조적 프로그래밍을 유지할 수 있게 된다.
✔️ 비동기 컨텍스트가 없을 때
그렇다면, 비동기 작업을 처리해야하는데 현재 비동기 컨텍스트에 있지 않다면 어떻게 해야할까. 새로운 Task를 생성하여 비동기 컨텍스트를 만들 수도 있지만, Task는 독립적인 흐름이 만들어지기 때문에 구조적 프로그래밍을 깨게 된다.
Swift는 계속해서 이러한 비구조적인 Task를 생성해야 하는 상황을 해결하기 위한 API를 추가하고 있다.
예를들어, SwiftUI는 뷰가 나타날 때 비동기 Task를 실행하고, 뷰가 사라질 때 Task를 취소하는 modifier를 제공한다.
import SwiftUI
Text("Hi")
.task {
let sum = try? await withThrowingTaskGroup(
of: Int.self, returning: Int.self
) { group in
// ...
}
print("sum", sum)
}.task 를 통해 비동기 작업을 실행할 수 있고, .task 내에서 실행되는 모든 하위 작업에 취소 신호가 전달된다. 이를 통해 구조적 프로그래밍을 유지할 수 있게 된다.
또 다른 예시로, 기존에는 Swift에서 최상위 레벨에서는 비동기 작업을 수행할 수 없었다.
try await Task.sleep(nanoseconds: NSEC_PER_SEC)
// Error: ‘async’ call in a function that does not support concurrency이러한 문제를 해결하려면 @main 을 사용하여 Entry point를 설정해 비동기 컨텍스트를 실행할 수 있는 환경을 만들어야 했다.
@main
struct Main {
static func main() async throws {
try await Task.sleep(nanoseconds: NSEC_PER_SEC)
print("done!")
}
}Swift 5.7부터는 이러한 문제가 해결되어 최상위 코드에서 비동기 작업을 바로 사용할 수 있게 되었다.
Apple의 프레임워크가 Swift의 동시성 도구와 깊이 통합됨에 따라 비구조적 Task를 생성할 필요가 거의 없어질 것으로 보인다.
Unstructured Concurrency
구조적 프로그래밍을 최대한 유지하는 것이 좋지만 그러지 못하는 경우도 존재한다. 새로운 Task를 생성하면 구조적 프로그래밍을 벗어나게 되지만, 부모 컨텍스트로부터 몇몇 기능을 상속받아 사용할 수 있게 된다.
✔️ Task의 상속
Task는 아래와 같이 TaskLocals와 우선순위를 상속받는 것을 확인할 수 있다.
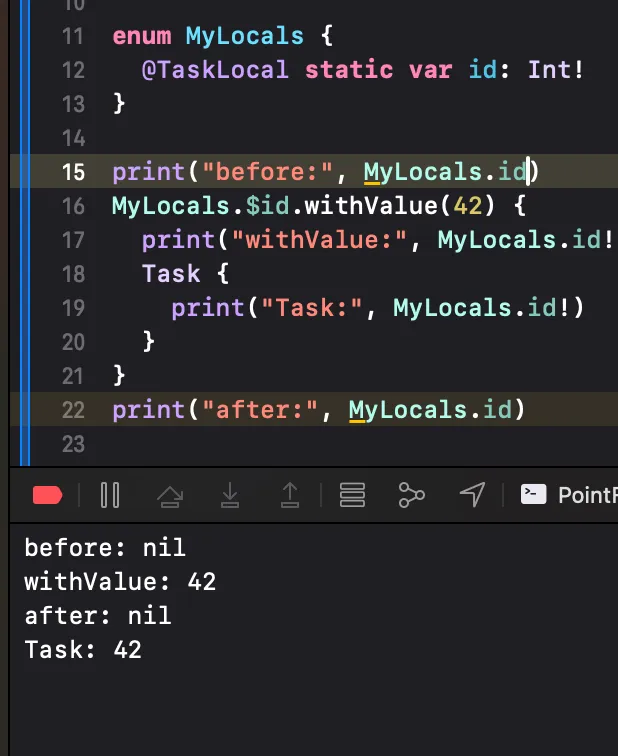

또, Task는 Actor를 상속받을 수 있다.
actor Counter {
var count = 0
func increment() {
self.count += 1
}
func decrement() async throws {
self.count -= 1
try await Task.sleep(nanoseconds: NSEC_PER_SEC / 2)
if self.count < 0 {
self.count += 1
}
}
}만일 위와 같이 decrement() 함수 내에서 count 가 0보다 작아질 경우 증가시켜주는 작업을 하고싶을 때, Task.sleep 을 이용하여 작업을 잠깐 중단하도록 하는 것은 바람직하지 않을 수 있다. 일단 값을 감소시키고 나중에 Actor가 자동으로 조정하도록 하고 싶을 수 있다.
이러한 경우 비 구조적 Task를 사용해볼 수 있다.
func decrement() {
self.count -= 1
Task {
try await Task.sleep(nanoseconds: NSEC_PER_SEC / 2)
if self.count < 0 {
self.count += 1
}
}
}이렇게 작성한다면 원하는대로 동작하는데, 위 코드에서 놀라운 부분이 있다.
지금까지 Actor 메서드와 프로퍼티에 접근하려고 할 때는 Actor 외부에서는 await 을 사용하여 접근해야 했다.

decrement()에서 Task는 Actor 내부에 존재하지만, Task는 Actor와 독립적인 흐름을 시작하게 된다. 그럼에도 불구하고 Actor 내부에 있는 Task 블록에서 await없이 프로퍼티와 메서드에 접근할 수 있는 이유는 Task가 Actor의 컨텍스트를 상속받기 때문이다. 그렇기 때문에 Task 안에서도 Actor 내부에서 동작하는 것 처럼 접근할 수 있다.
이러한 기능은 구조적인 프로그래밍이 아니어도 쉽게 이해할 수 있게 만들어준다.
✔️ 분리된 Task에서의 Actor
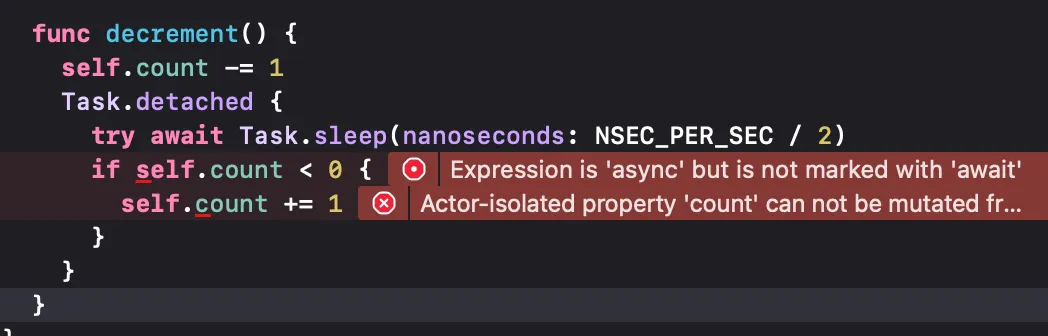
반면에, 현재 컨텍스트에서 완전히 분리된 Task를 생성할 수 있다. 이는 우선순위, Task Local값, actor를 상속받지 않는다.
Task.detached {
}
이제는 await 을 통해 접근해야 한다.
func decrement() {
self.count -= 1
Task.detached {
try await Task.sleep(nanoseconds: NSEC_PER_SEC / 2)
if await self.count < 0 {
await self.increment()
}
}
}분리된 Task는 완전히 초기화 된 상태에서 시작하게 된다. 뿐만아니라 구조적인 동시성을 위한 도구 중 일부도 현재 Task의 요소를 상속받지 않는 것이 있다.
@Sendable, async let, Taskgroup은 현재 actor의 컨텍스트를 상속받지 못한다.
예를들어, 동기 클로저 내부에서 actor 프로퍼티에 접근하는 것은 문제가 발생하지 않는다.
func increment() {
self.count += 1
let count = { self.count }()
}
하지만, @Sendable 을 적용하게 되면 컴파일 오류가 발생하게 된다.

이러한 문제를 해결하려면 비동기 컨텍스트를 제공하여 await 을 사용하여 접근해야 한다.
func increment() async {
let count = await { @Sendable in await self.count }()
}
Task가 어떻게 Actor 컨텍스트를 상속받을까?
Task는 공개적으로 노출되지 않은 특수 컴파일러의 속성을 통해 actor 컨텍스트를 상속하게 된다.
public init(
priority: TaskPriority? = nil,
@_inheritActorContext
@_implicitSelfCapture
operation: __owned @Sendable @escaping () async -> Success
) {Actor 컨텍스트를 상속 받는 것은 Task에 적용되어있는 내용이기 때문이다.
@Sendable 과 마찬가지로 async let 또한 상속받지 못한다.

async let은 비동기적으로 실행되는 작업을 동시에 실행하기 위해 사용된다. 다른 작업과 병렬적으로 실행되야 하기 때문에 클로저를 자동으로 @Sendable 속성으로 변환된다.
그렇기 때문에 async let은 actor 격리를 유지하지 않게 되어 actor의 프로퍼티에 접근할 수 없게 된다. 이 오류를 해결하기 위해서는 await 을 사용하여 접근하는 것이다.
func increment() async {
async let count = { await self.count }()
}
Task group도 상속받지 못한다. 예시로 1000개의 작업을 생성하여 count를 증가 또는 감소시키는 메서드를 구현해보자.

오류가 발생하는 이유는 addTask 클로저는 @Sendable 클로저이기 때문에 현재 actor를 상속받지 못한다. 그렇기 때문에 비동기 컨텍스트를 사용하여 접근해야 한다.
group.addTask {
if Bool.random() {
await self.increment()
} else {
await self.decrement()
}
}MainActor
MainActor의 필요성
Swift 동시성 도구를 사용할 때 스레드에 대해 고려할 필요가 거의 없다. 하지만 특정 작업을 수행할 때 메인 스레드에서 실행되도록 해야 할 경우가 있다.
이전에 살펴본 바와 같이 작업을 Task.sleep 과 같이 중단한 이후 다시 작업을 재개할 경우 기존에 사용하던 스레드가 아닌 다른 스레드에서 시작하게 될 수 있다. 하지만 이전과 동일한 특정 스레드(예: 메인 스레드)에서 실행해야 할 경우는 어떻게 해야할까?
예를들어, count 변수를 가지고 있고, 복잡한 연산을 수행하는 비동기 메서드를 포함하고 있는 ObservableObject 가 있다고 가정해보자.
class ViewModel: ObservableObject {
@Published var count = 0
func perform() async throws {
try await Task.sleep(nanoseconds: NSEC_PER_SEC)
self.count = .random(in: 1...1_000)
}
}위 코드는 경고 없이 컴파일되지만 잘못된 코드이다. self.count 를 변경하는 코드가 어떤 스레드에서 실행될 지 알 수 없다. 하지만 count 는 @Published 로 선언했고, @Published는 반드시 메인 스레드에서 변경되어야 한다.
메인 스레드에서 동작하도록 하기 위해 DispatchQueue.main.async 를 생각해볼 수 있을 것이다.
class ViewModel: ObservableObject {
@Published var count = 0
func perform() async throws {
try await Task.sleep(nanoseconds: NSEC_PER_SEC)
DispatchQueue.main.async {
self.count = .random(in: 1...1_000)
}
}
}위 코드는 오류가 발생하는데, ViewModel이 Sendable 타입이 아니기 때문이다. 그렇기 때문에 self를 캡쳐할 수 없다. ViewModel은 가변 데이터를 포함하고 있기 때문에 쉽게 Sendable 로 만들 수 없다.
게다가, DispatchQueue 의 async는 전달되는 클로저가 Sendable 이어야 한다고 요구하기 때문에 Sendable 타입이 아닌 데이터를 캡쳐할 수 없다.
따라서, 이는 안전한 동시성 코드가 아니게 된다. 새로운 형태의 동시성을 비동기 코드와 섞어 사용하게되면서 Swift의 기본 동시성 도구가 제공하는 장점들을 사용하지 못하게 된다.
예를들어, 메인 큐로 Dispatch하게되면서 Task Locals를 상속할 수 없게 된다.
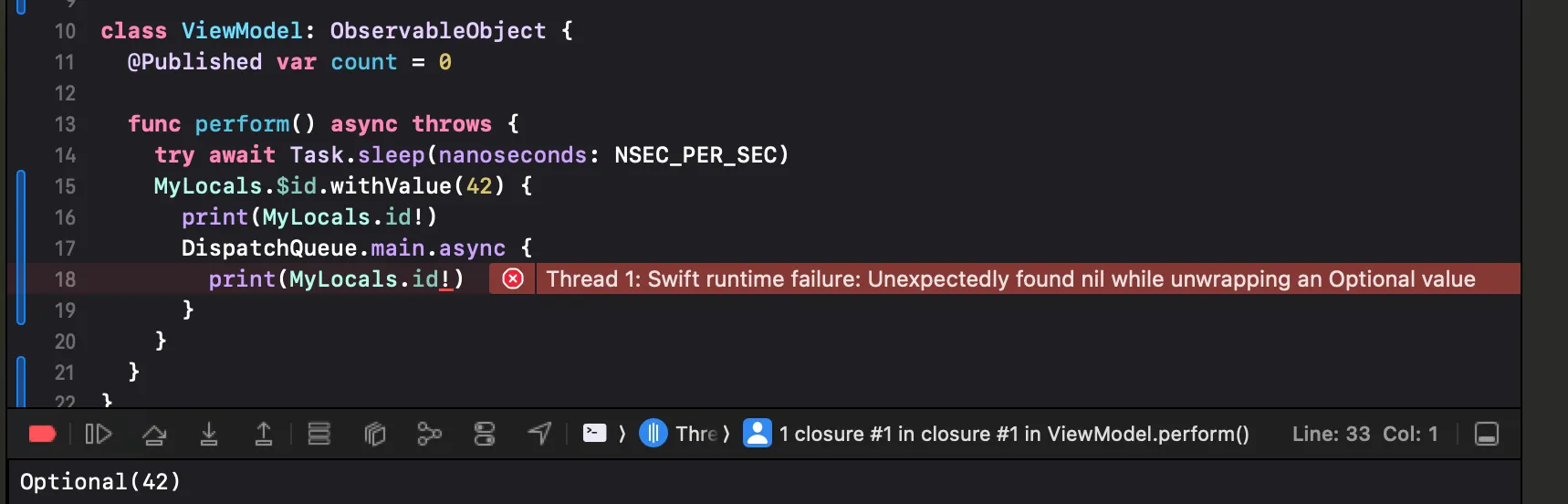
DispatchQueue.main.async 클로저 내에서 접근할 때 런타임 오류가 발생하는 것을 볼 수 있다.
이러한 문제가 발생하는 이유는 Task Local이 withValue 클로저의 수명 동안만 접근할 수 있기 때문이다. 이 클로저는 non-escaping이고, 동기적으로 호출되기 때문이다.
더 명확하게 실행 범위를 확인해보면,

withvalue 가 종료된 이후에 DispatchQueue.main.async 가 실행되는 것을 볼 수 있다.
MainActor
그래서 우리는 메인 스레드에서 강제로 실행하기 위한 안전한 방법을 찾아야 한다.
스레드가 메인 스레드라는 개념을 가지고 있고, DispatchQueue가 메인 큐를 가지고 있는 것 처럼, Actor에는 MainActor라는 개념이 존재한다.

MainActor 타입은 메인 스레드에서 동기적으로 클로저를 실행할 수 있는 Endpoint를 제공한다.
await MainActor.run {
...
}MainActor의 run 메서드를 호출하려면 await키워드를 사용해야 한다. 다른 작업이 이미 메인 스레드에서 동작중일 경우 시간이 걸릴 수 있기 때문이다.
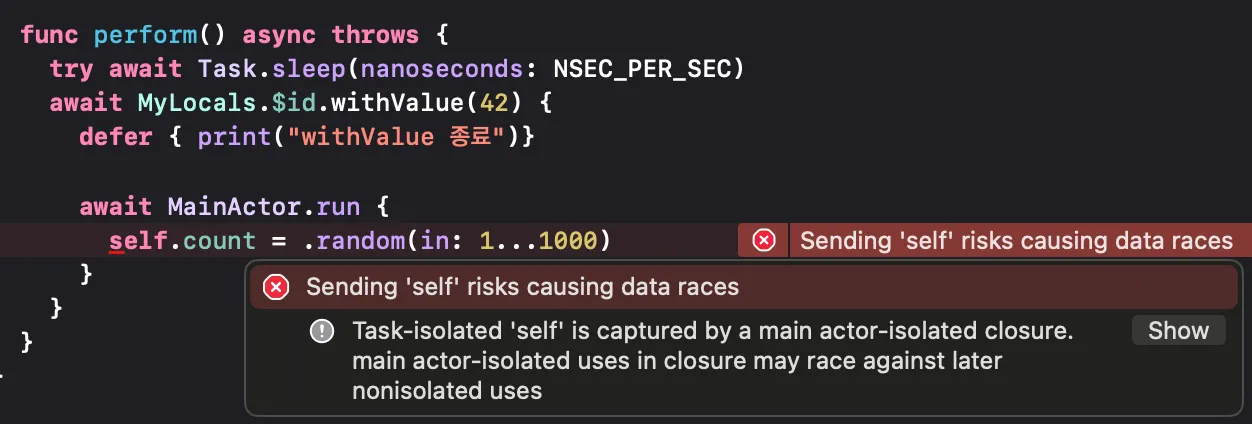
위와 같이 MainActor.run에서 count 를 변경하려 하면 오류가 발생한다. Non-Sendable 타입의 데이터를 수정해야 하기 때문에 race condition이 발생할 가능성이 있다.
await MainActor.run {
self.count = .random(in: 1...1_000)
}
await MainActor.run {
self.count = .random(in: 1...1_000)
}
이러한 문제를 해결하기 위해 메서드에 MainActor 속성을 부여할 수 있다.
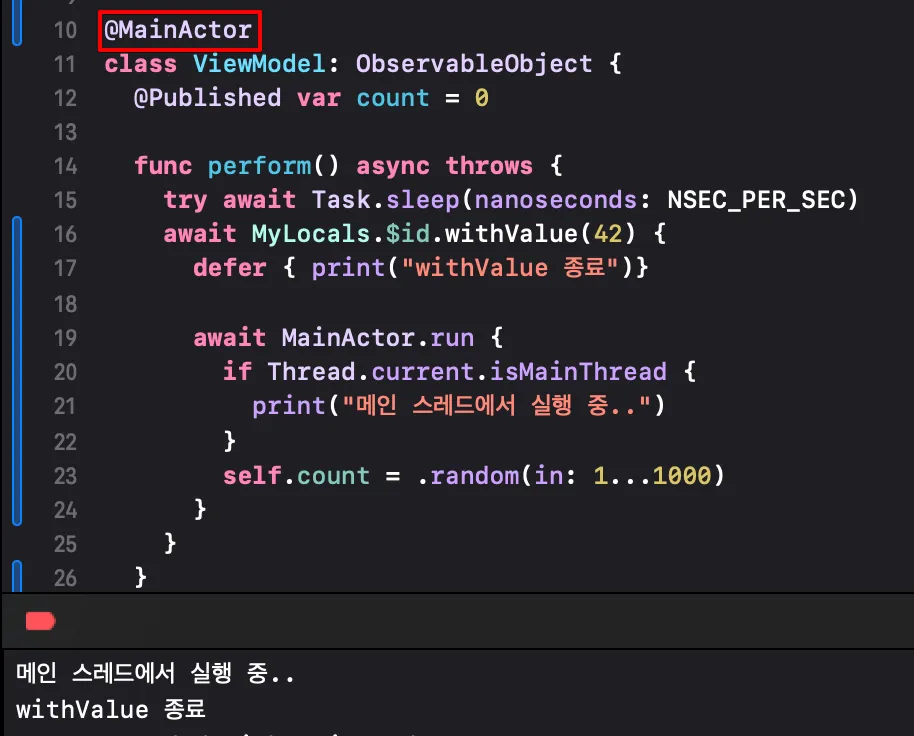
메서드가 @MainActor 로 표시되었다고 해서 모든 것이 메인스레드에서 동작하는 것은 아니다. 다른 비동기 메서드를 호출하거나 Task.sleep 등 현재 작업의 일시 중단 지점에서는 다른 스레드에서 동작할 수 있다. @MainActor 로 표시된 메서드 내에서도 비동기적이고 병렬적인 작업을 수행할 수 있다.
또한, 메서드 내에서 sleep 을 호출한다고 해서 메인 스레드를 blocking하지는 않는다. sleep 이 실행되는 동안 다른 작업이 MainActor에서 실행될 수 있다.
하지만, 메인 스레드에서 많은 리소스를 사용하는 작업을 하게 되면 메인 스레드가 차단될 수 있는 문제가 있다.
메서드 뿐만아니라 클래스에도 @MainActor 를 적용해 볼 수 있다.
@MainActor
class ViewModel: ObservableObject {
...
}클래스에 적용하면 모든 생성자, 메서드 프로퍼티가 모두 @MainActor 로 표시된다. 또한, 클래스 전체를 @Sendable로 만들며, 이 클래스가 병렬적인 컨텍스트에서도 안전하게 사용될 수 있음을 보장한다.
@MainActor 를 선언함으로써 모든 상호작용이 메인 스레드에서 직렬화되어 사용할 수 있게 된다.
Task를 사용하면 자동으로 Actor 컨텍스트를 상속받게 된다. 따라서 아래 코드는 메인스레드에서 실행된다.
@MainActor
func perform() async throws {
Task {
print(Thread.current)
}
}<_NSMainThread: 0x10600a9b0>{number = 1, name = main}
반면, Task.detached를 사용하면 Actor 컨텍스트를 상속받지 않으며, 백그라운드에서 실행된다.
@MainActor
func perform() async throws {
Task.detached {
print(Thread.current)
}
}
비슷하게 async let 이나 Task Group과 같은 비동기 병렬 구조를 MainActor 코드에 도입하면 해당 작업은 메인스레드가 아닌 다른 스레드에서 실행된다.
@MainActor를 활용하면 메인 스레드에서의 안전한 작업 관리가 가능해지며, 병렬 실행과 적절한 조화를 이룰 수 있다.
✔️ 단일 스레드에서의 동시성
우리는 지금까지 어떤 작업이 어떤 스레드에서 실행 되는지 확인해왔다. 하지만 스레드에 대해 생각하지 않고 하나의 스레드에서 모든 작업을 실행할 수도 있다. 실제로 단일 스레드로 동작하고 있는 환경이 많다. 예를들어, 웹어셈블리와 몇몇 라즈베리파이 모델이 단일 스레드로 동작한다.
따라서 이러한 상황에도 비동기성과 동시성을 처리할 수 있는 방법이 있는 것은 강력한 기능이다.
이를 알아보기 위해 여러 작업을 실행하면서 모든 작업이 메인스레드에서 실행되도록 강제해보자.
0.25초마다 로그를 출력하는 작업을 수행하고,
await withThrowingTaskGroup(of: Void.self) { group in
group.addTask { @MainActor in
while true {
try await Task.sleep(nanoseconds: NSEC_PER_SEC / 4)
print(Thread.current, "Timer ticked")
}
}
}
동시에 2,000,000번째 소수를 계산하는 작업을 수행한다. 이 작업은 많은 시간을 소모하게 된다.
group.addTask { @MainActor in
nthPrime(2_000_000)
}
또, 동시에 대용량 파일 1,000개 다운로드 작업을 수행한다.
for n in 0..<workCount {
group.addTask { @MainActor in
_ = try await URLSession.shared
.data(from: .init(string: "http://ipv4.download.thinkbroadband.com/1MB.zip")!)
print(Thread.current, "Download finished", n)
}
}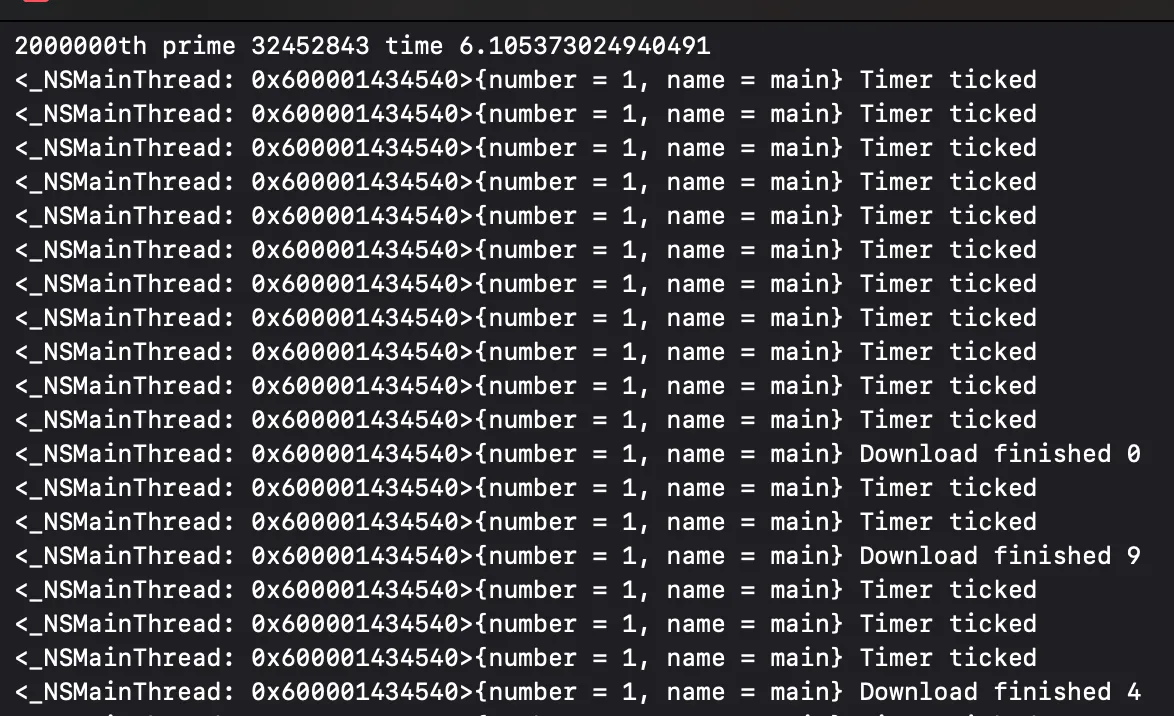
위 작업을 수행하면 초기에는 로그가 출력되지 않다가, 약 6초 후에 로그가 출력된다. 소수를 계산하는 함수가 매우 강력한 연산을 수행하게되며 메인스레드를 묶어버리기 때문이다.
그렇다면 소수 계산 함수를 비동기로 변경하고, 1000번마다 다른 작업이 실행될 수 있도록 양보(yield)해보자.
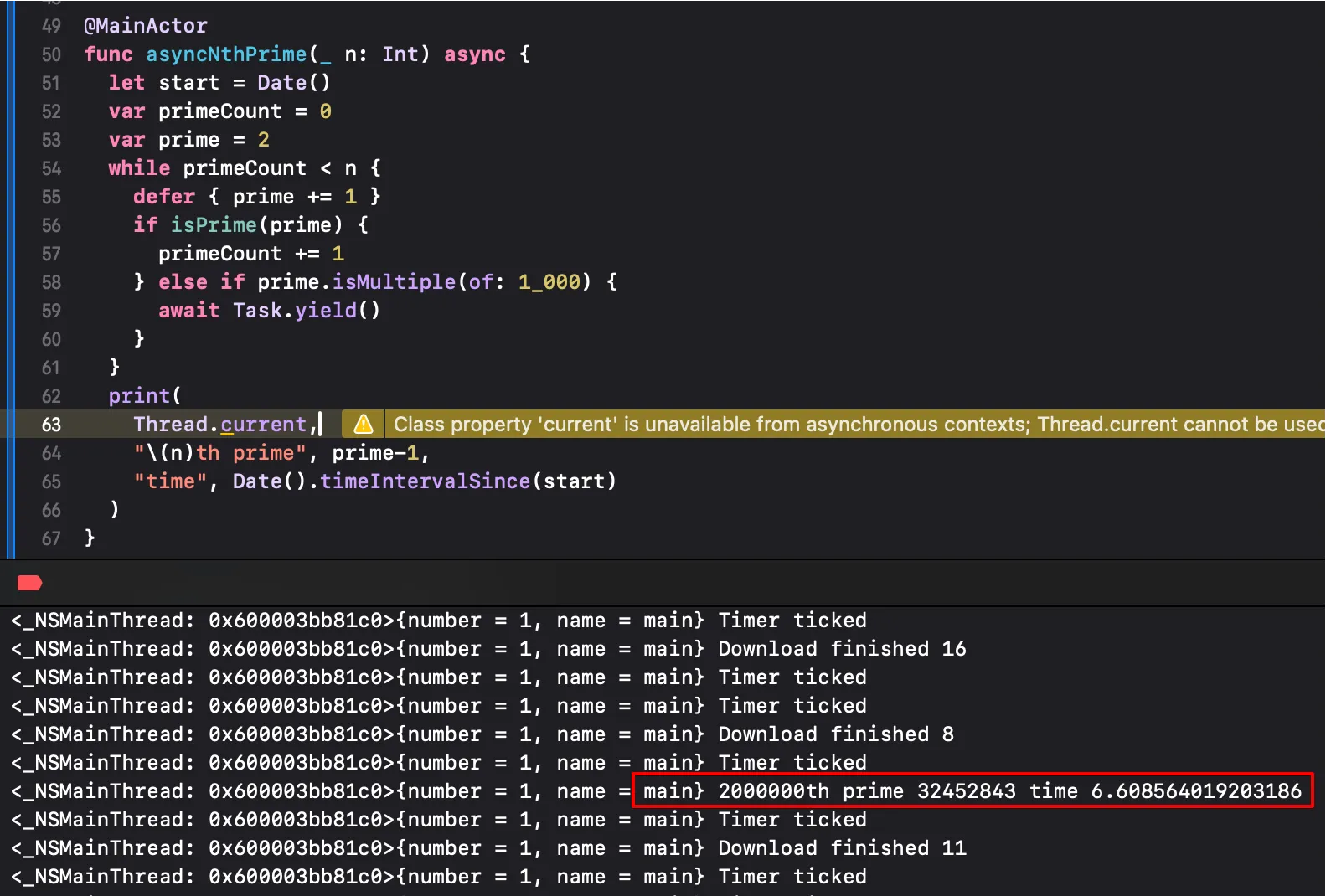
실행 즉시 로그가 출력되고, 여러 작업이 동시에 실행된다. 그리고 약 6초 후 소수 계산 결과가 출력된다.
단일 스레드에서도 효율적인 비동기 작업 처리가 가능하며, 작업간 차단을 최소화하여 동시성을 극대화할 수 있다.
PointFree 강의를 듣고 정리한 내용입니다!
https://www.pointfree.co/episodes/ep194-concurrency-s-future-structured-and-unstructured
Episode #194: Concurrency's Future: Structured and Unstructured
There are amazing features of Swift concurrency that don’t quite fit into our narrative of examining it through the lens of past concurrency tools. Instead, we’ll examine them through the lens of a past programming paradigm, structured programming, and
www.pointfree.co
'iOS > Swift' 카테고리의 다른 글
| [iOS/Point-Free] 동시성프로그래밍: Sendable, Actor (0) | 2024.12.30 |
|---|---|
| [iOS/Point-Free] 동시성프로그래밍: Task (2) | 2024.12.18 |
| [iOS/Point-Free] 동시성 프로그래밍: OperationQueue, CGD와 Combine (1) | 2024.12.11 |
| [iOS/Point-Free] 동시성 프로그래밍의 과거 - 스레드 (1) | 2024.11.25 |
| [iOS/Swift] 인앱에서 앱스토어 리뷰 팝업 띄우기 (0) | 2024.10.24 |